I recently watched a pretty inspiring talk by Avi Press about his experience using Haskell at his startup, Scarf. I enjoyed the whole talk, but something that particularly got me excited was his point that although Haskell is pure, in practice, almost all the code his company was writing ended up being monadic. One simple reason was the need for logging through the codebase. And this really struck a chord with me, because in my experience as a maybe late beginner Haskeller (I would love to discover I am early intermediate, but I doubt it), one of the most frustrating things has been how difficult it can be to debug some pretty large piece of code. Yes, because everything is pure, I could just call functions in ghci, for example, to see if I am getting what I expect. But creating the environment for such calls is a problem — and a well-known one at that, in the world of testing. And unless you want to put every function that you might need logging for into the IO monad (or ok, maybe some more particular monad), you are not going to have access to this very standard debugging practice of printing messages from functions to see what is going on. This is a pretty huge problem for software engineering with Haskell, and it is surprising that there is relatively little said about it.
So Haskell’s promise of purity is getting badly undercut by this simple need to log. It is great that the language is pure, but if you have to use the IO monad everywhere for logging, then you are greatly reducing the number of pure functions in your codebase, and that is sad.
From a research perspective, I am working on DCS, which has an even stricter core language than Haskell’s: pure and also uniformly terminating (all functions are statically checked for termination at compile-time using a novel type-based approach). And there, I am also concerned that if it is too hard to fit one’s functions in that core, then again, DCS programs will get overtaken by monadic code (in a Div monad for possibly diverging computations).
Now in both DCS and Haskell, a pretty simple generalization of the notion of purity would seem sufficient to solve this problem. It should be fine to let a program perform computation in the IO monad, as long as one is not allowed to use the value produced by such a computation, in pure code. So I imagine having a safePerformIO function, like this (in Haskell):
safePerformIO :: IO () -> a -> a
safePerformIO m x = unsafePerformIO m `seq` xThe idea is that we use unsafePerformIO under the hood, and seq to make sure the IO actually happens. But a pure computation x cannot possibly depend on what the IO does, since we just use a computation of type IO (), which does not produce a value within the language. It could happen that the IO computation fails somehow, for example by raising an exception. But even pure code in Haskell can do that, so it does not seem to compromise the purity of pure functions. In DCS, the situation would be different, and one would need to have a library of IO functions that cannot fail (or diverge) to use this idea for DCS code. Otherwise, the core language would not be able to guarantee that functions in the core are guaranteed to terminate (because some code used with safePerformIO had failed with an exception or diverged).
For a very simple approach to logging (no logging levels, for example), we can have some code like this:
logInit :: FilePath -> IO Handle
logInit f =
do
h <- openFile f WriteMode
hSetBuffering h NoBuffering
return h
log :: Handle -> String -> a -> a
log h msg x = safePerformIO (hPutStr h msg) xWe have a function to get a handle for logging, and then another that uses safePerformIO to write a message to the log.
I am planning to use this approach to logging in my Haskell codebase for DCS, because it is just so useful to be able to log some information while trying to debug a complex piece of code. And I do not want to put everything into a monad just to do that.
Thanks for reading! Drop me a line at aaron.stump@gmail.com or comment here, if you have feedback or thoughts.
 and
and 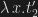 , respectively, with t1′ and t2′ normal. So we have that for any closed t, [t/x]t1′ =beta [t/x]t2′. Instantiate this with
, respectively, with t1′ and t2′ normal. So we have that for any closed t, [t/x]t1′ =beta [t/x]t2′. Instantiate this with 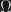 , which is
, which is 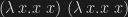 , and write c1 for [Omega/x]t1′, and c2 for [Omega/x]t2′. Suppose that x is not free in t1′. Then we have t1′ =beta c2. By the Church-Rosser property of untyped lambda calculus, this implies that c2 beta-reduces to t1′, since t1′ is normal. But this can only happen if x is not free in t1′ and t1′ is identical to t2′. Otherwise, c2 would lack any normal form.
, and write c1 for [Omega/x]t1′, and c2 for [Omega/x]t2′. Suppose that x is not free in t1′. Then we have t1′ =beta c2. By the Church-Rosser property of untyped lambda calculus, this implies that c2 beta-reduces to t1′, since t1′ is normal. But this can only happen if x is not free in t1′ and t1′ is identical to t2′. Otherwise, c2 would lack any normal form.